Visualization
Loading required packages
library(tidyverse)
library(usmap)
library(knitr)
library(here)
library(dplyr)
library(scales)
library(lubridate)##
## Attaching package: 'lubridate'## The following objects are masked from 'package:base':
##
## date, intersect, setdiff, unionFor this exercise, I’ll recreate a graphic from FiveThirtyEight which demonstrates how Scrabble scores increased following a rule change incorporating new words. The link to the original article can be found here
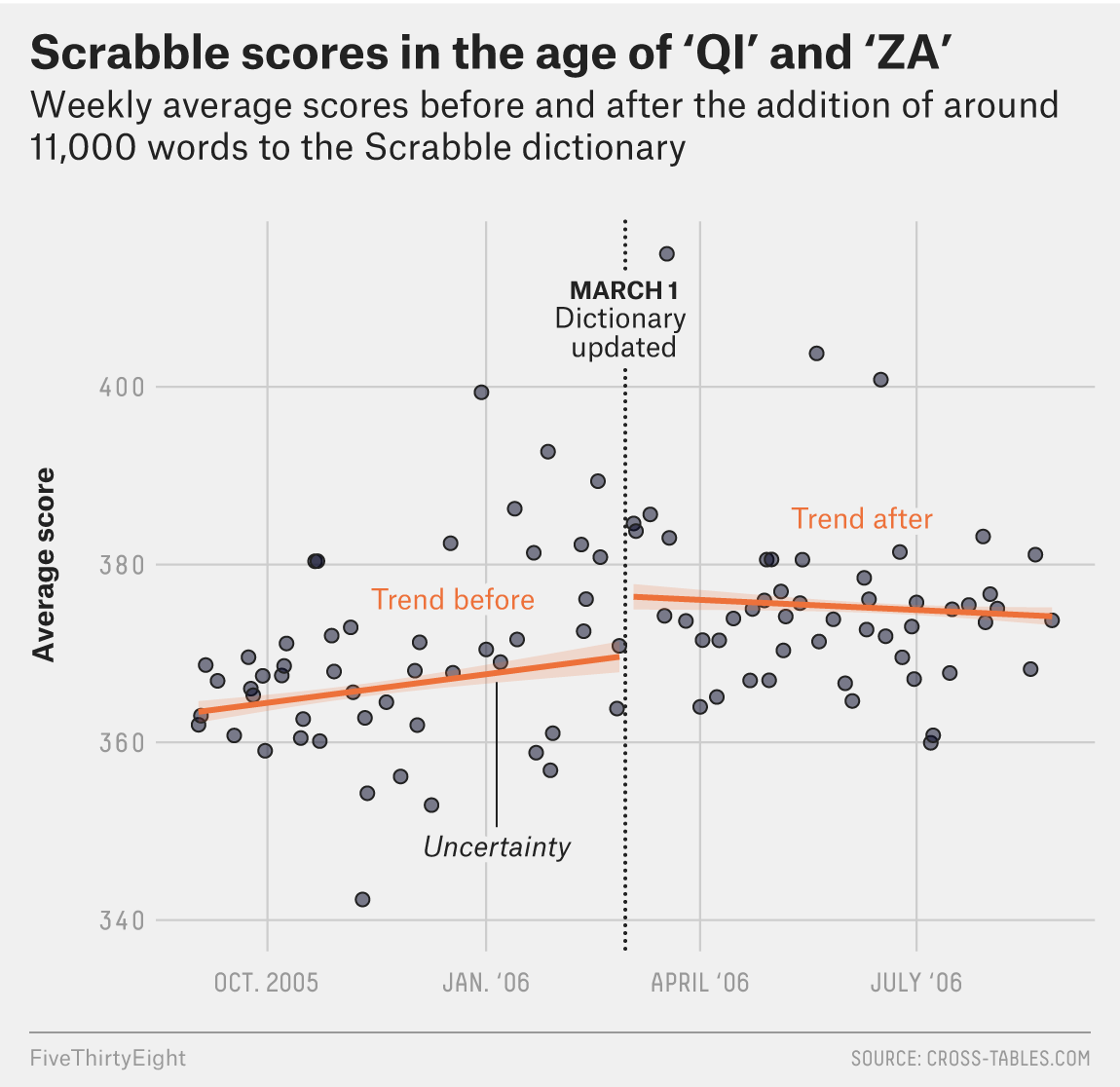
The visual I want to recreate
Loading data
file <- "https://media.githubusercontent.com/media/fivethirtyeight/data/master/scrabble-games/scrabble_games.csv"
data <- read.csv(file, header = TRUE)Look at data
dplyr::glimpse(data)## Rows: 1,542,642
## Columns: 19
## $ gameid <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,…
## $ tourneyid <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, …
## $ tie <chr> "False", "False", "False", "False", "False", "False", …
## $ winnerid <int> 268, 268, 268, 268, 268, 268, 268, 268, 429, 429, 429,…
## $ winnername <chr> "Harriette Lakernick", "Harriette Lakernick", "Harriet…
## $ winnerscore <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
## $ winneroldrating <int> 1568, 1568, 1568, 1568, 1568, 1568, 1568, 1568, 1915, …
## $ winnernewrating <int> 1684, 1684, 1684, 1684, 1684, 1684, 1684, 1684, 1872, …
## $ winnerpos <int> 1, 1, 1, 1, 1, 1, 1, 1, 3, 3, 3, 3, 3, 3, 5, 5, 5, 5, …
## $ loserid <int> 429, 435, 441, 456, 1334, 454, 5766, 442, 456, 1334, 4…
## $ losername <chr> "Patricia Barrett", "Chris Cree", "Caesar Jaramillo", …
## $ loserscore <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
## $ loseroldrating <int> 1915, 1840, 1622, 1612, 1537, 1676, 1647, 1739, 1612, …
## $ losernewrating <int> 1872, 1798, 1606, 1600, 1590, 1647, 1640, 1747, 1600, …
## $ loserpos <int> 3, 6, 10, 9, 4, 8, 7, 2, 9, 4, 5, 6, 6, 5, 6, 8, 1, 10…
## $ round <int> 1, 2, 3, 4, 6, 8, 9, 10, 3, 5, 6, 9, 10, 11, 3, 4, 7, …
## $ division <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, …
## $ date <chr> "1998-12-06", "1998-12-06", "1998-12-06", "1998-12-06"…
## $ lexicon <chr> "False", "False", "False", "False", "False", "False", …There are a good amount of variables in this dataset, but I know I mainly need the date and score variables, so I can clean up this dataset a bit. There are also some observations with negative scores or scores of 0 for both the winner and the loser, so let’s eliminate those. I’m filtering to keep winning scores greater than 0 (assuming that winning scores recorded as 0 are incorrect/not possible) and losing scores greater than or equal to 0 (assuming a losing score of 0, recorded with a an actual winning score, is correct) # Wrangling data
cleandata <- data %>% select("winnerscore", "loserscore", "date") %>% filter(winnerscore>0, loserscore>=0)The visualization that I want to recreate does not discern between winning and losing scores, but just uses average score. Next, I need to combine the winning and losing score variables into one variable, average score. Another option is to gather the data into tidy format so that all of the scores fall under the same variable. Let’s try that # Consolidating scores
cleandata <- gather(cleandata, key = result, value = score, 1:2) %>% select(date, score)Now we just have dates and scores. In the visualization, scores are averaged by week. Let’s see how the scatterplot looks before attempting this. # Initial scatterplot
cleandata %>% ggplot(aes(x = date, y = score)) + geom_point()
This plot is a mess - let’s continue to clean up the data by focusing on 2005 - present, which are the dates from the original figure. I’m having trouble filter the data though.
class(cleandata$date)## [1] "character"Now I see that the date column is a character Let’s see if we can fix that.
Convert character to date
cleandata <- cleandata %>% mutate(date = as.Date(cleandata$date, format = "%Y-%m-%d"))
summary(cleandata)## date score
## Min. :1976-12-05 Min. : 0.0
## 1st Qu.:2007-04-13 1st Qu.:333.0
## Median :2010-02-06 Median :373.0
## Mean :2009-05-22 Mean :375.8
## 3rd Qu.:2013-04-13 3rd Qu.:415.0
## Max. :2017-03-05 Max. :803.0class(cleandata$date)## [1] "Date"Now it looks like we’ve successfully classified the date column. Now let’s try filtering again. # Filter dates
cleandata <- cleandata %>% filter(date>="2005-08-01" & date<="2006-08-01")Preview plot again
cleandata %>% ggplot(aes(x = date, y = score)) + geom_point()
At this point, I think the main thing I need to do is group the scores by week and average them.
Assign weeks to scores
weekdata <- cleandata %>% group_by(week = floor_date(date, "1 week")) %>% select(week, score) %>% glimpse()## Rows: 80,144
## Columns: 2
## Groups: week [51]
## $ week <date> 2005-08-21, 2005-08-21, 2005-08-21, 2005-08-21, 2005-08-21, 200…
## $ score <int> 404, 433, 450, 323, 432, 524, 341, 452, 444, 409, 413, 449, 465,…Now, we have the scores assigned to weeks. From here, we can figure out the average score for each week.
Average scores
weekdata <- weekdata %>% group_by(week) %>% summarize(avg_score=mean(score))
summary(weekdata)## week avg_score
## Min. :2005-08-14 Min. :357.8
## 1st Qu.:2005-11-09 1st Qu.:365.1
## Median :2006-02-05 Median :372.3
## Mean :2006-02-05 Mean :372.1
## 3rd Qu.:2006-05-03 3rd Qu.:376.0
## Max. :2006-07-30 Max. :405.4glimpse(weekdata)## Rows: 51
## Columns: 2
## $ week <date> 2005-08-14, 2005-08-21, 2005-08-28, 2005-09-04, 2005-09-11,…
## $ avg_score <dbl> 369.0843, 376.5833, 362.4530, 365.2479, 358.7208, 365.6656, …Now, I think the data is ready to go for the plot. Let’s see what the scatterplot looks like now
Preview plot
weekdata %>% ggplot(aes(x = week, y = avg_score)) + geom_point()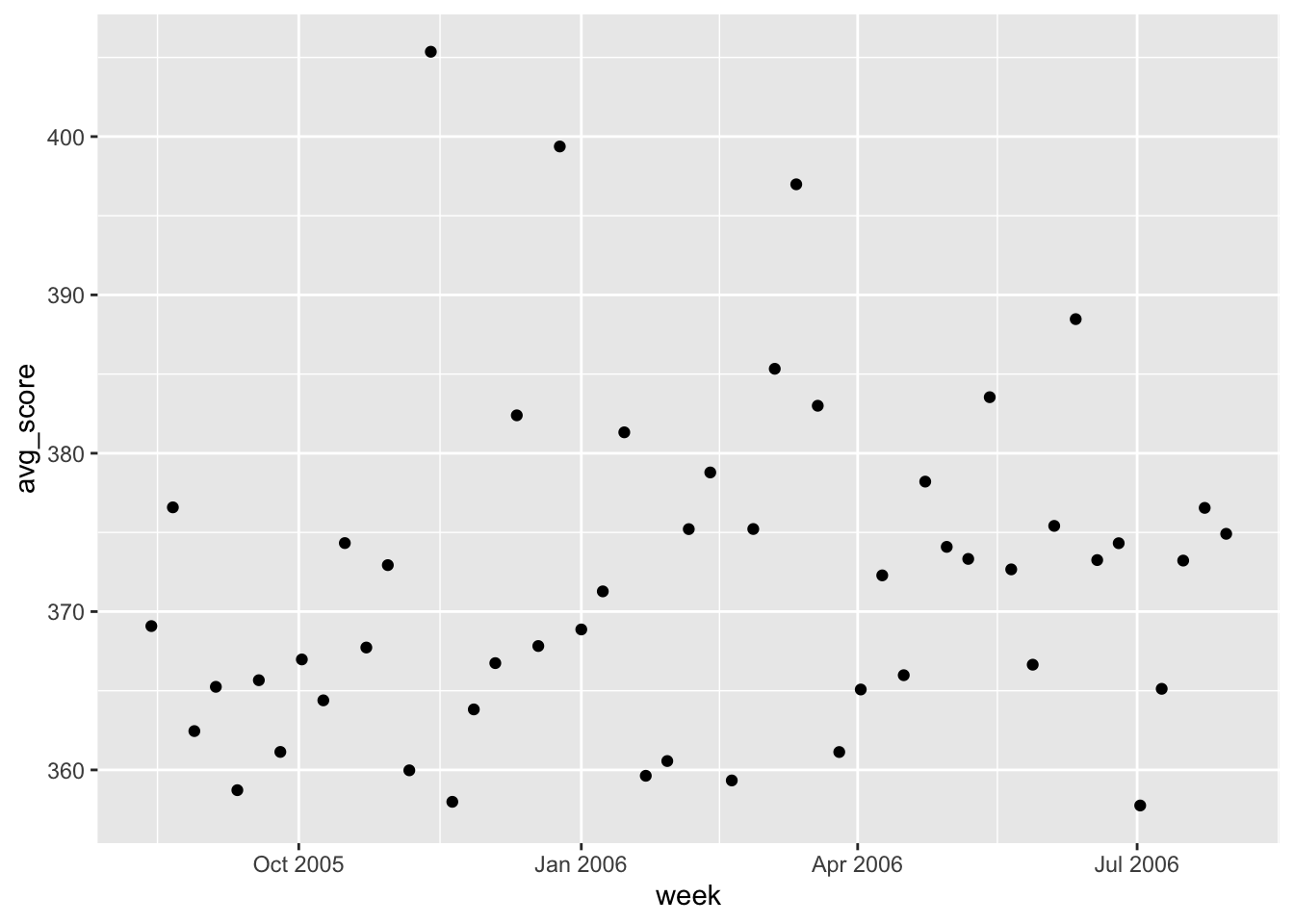
It looks like we have the correct date range for the graph. Let’s edit the labels and graph titles to match the original.
Attempt to edit axis labels
weekdata %>% ggplot(aes(x = week, y = avg_score)) + geom_point() + scale_x_date(date_breaks = "3 months", date_labels = "%b-%y")
I could use date_labels to adjust the format to say the full or abbreviated month names, or use the full or abbreviated years. However, in the original figure, there is a mixture of formats for the labelling so I am not sure how to approach formatting the individual ticks. Let’s move on for now.
Editing labels
#removing x axis label, adding y axis label
weekdata %>% ggplot(aes(x = week, y = avg_score)) + geom_point() + theme(axis.title.x=element_blank()) + ylab("Average score")
I also should adjust the scale of the y axis to match the original (340 to 400, by 20)
Adjust plot range
weekdata %>% ggplot(aes(x = week, y = avg_score), ylim=c(340, 400)) + geom_point() + theme(axis.title.x=element_blank()) + ylab("Average score") + scale_y_continuous(breaks = c(340, 360, 380, 400), limits = c(340, 420))
Now let’s try to add the line for the March 1st change in rules # Add line marking date of rule change
weekdata %>% ggplot(aes(x = week, y = avg_score), ylim=c(340, 400)) + geom_point() + theme(axis.title.x=element_blank()) + ylab("Average score") + scale_y_continuous(breaks = c(340, 360, 380, 400), limits = c(340, 420)) + geom_vline(aes(xintercept = as.numeric(week[30])))
I had trouble getting a line at the March 5, 2006 date, but eventually decided to use the column number for the week of March 5, which is column 60. Now let’s see if we can make the line dashed and add some text. # Labelling the line
weekdata %>% ggplot(aes(x = week, y = avg_score), ylim=c(340, 400)) + geom_point() + theme(axis.title.x=element_blank()) + ylab("Average score") + scale_y_continuous(breaks = c(340, 360, 380, 400), limits = c(340, 420)) + geom_vline(aes(xintercept = as.numeric(week[30])))+
annotate(geom="text",x=as.Date("2006-03-05"),
y=410,label="MARCH 1",fontface="bold")+
annotate(geom="text",x=as.Date("2006-03-05"),
y=405,label="Dictionary updated")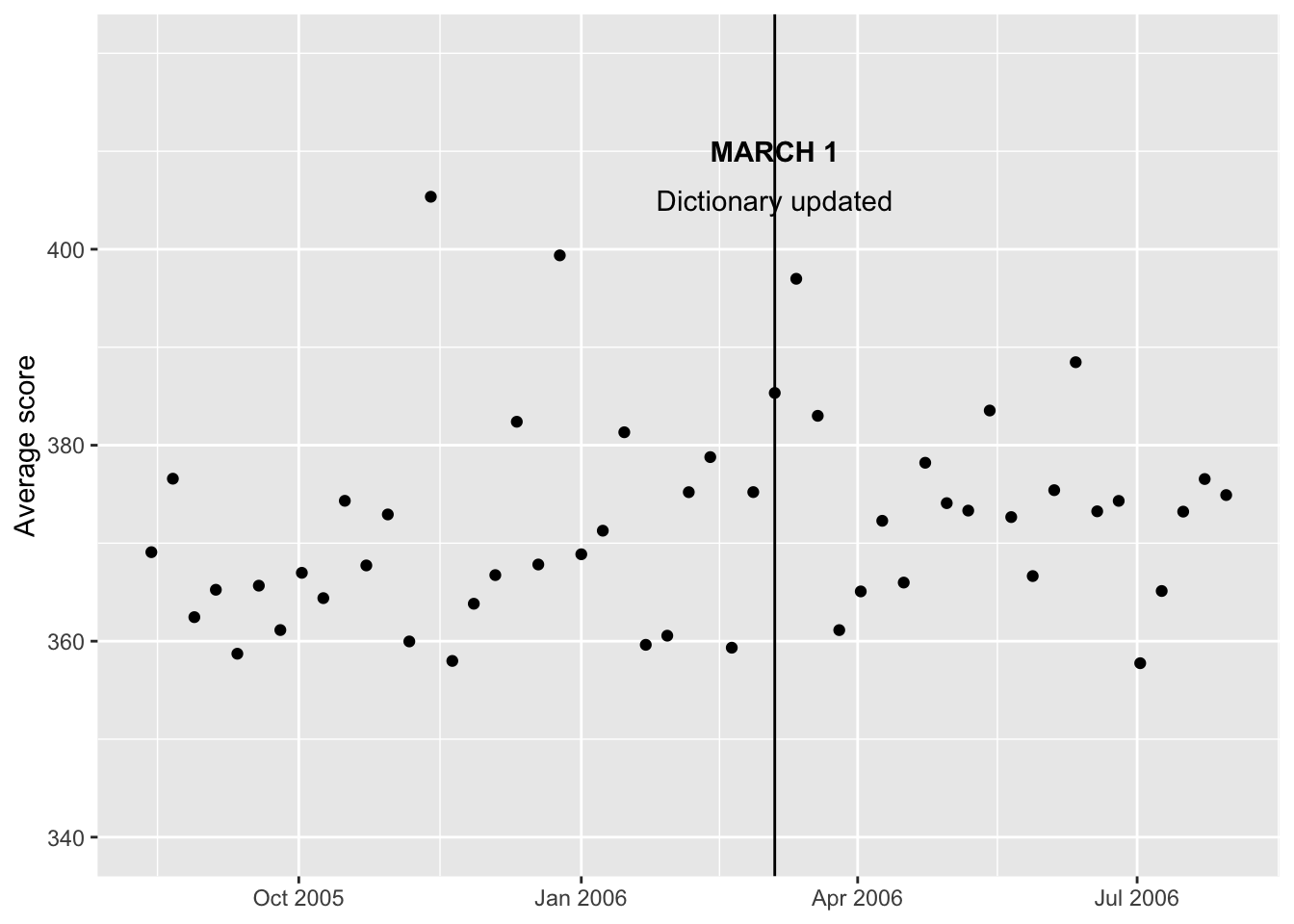
Next, I can focus on adding the trendlines. Some Googling helped me figure out how to separate the trendline into segments.
Add trendlines
weekdata %>% ggplot(aes(x = week, y = avg_score), ylim=c(340, 400)) + geom_point() + theme(axis.title.x=element_blank()) + ylab("Average score") + scale_y_continuous(breaks = c(340, 360, 380, 400), limits = c(340, 420)) + geom_vline(aes(xintercept = as.numeric(week[30])))+
annotate(geom="text",x=as.Date("2006-03-05"),
y=410,label="MARCH 1",fontface="bold")+
annotate(geom="text",x=as.Date("2006-03-05"),
y=405,label="Dictionary updated")+
stat_smooth(method = "lm", formula = y ~ x, size = 0.75, se = TRUE, level = 0.40,
color = "red", fill = "red", alpha = 0.2,
data = weekdata[weekdata$week < as.Date("2006-03-05"),]) +
stat_smooth(method = "lm", formula = y ~ x, size = 0.75, se = TRUE, level = 0.40,
color = "forestgreen", fill = "forestgreen", alpha = 0.2,
data = weekdata[weekdata$week >= as.Date("2006-03-05"),])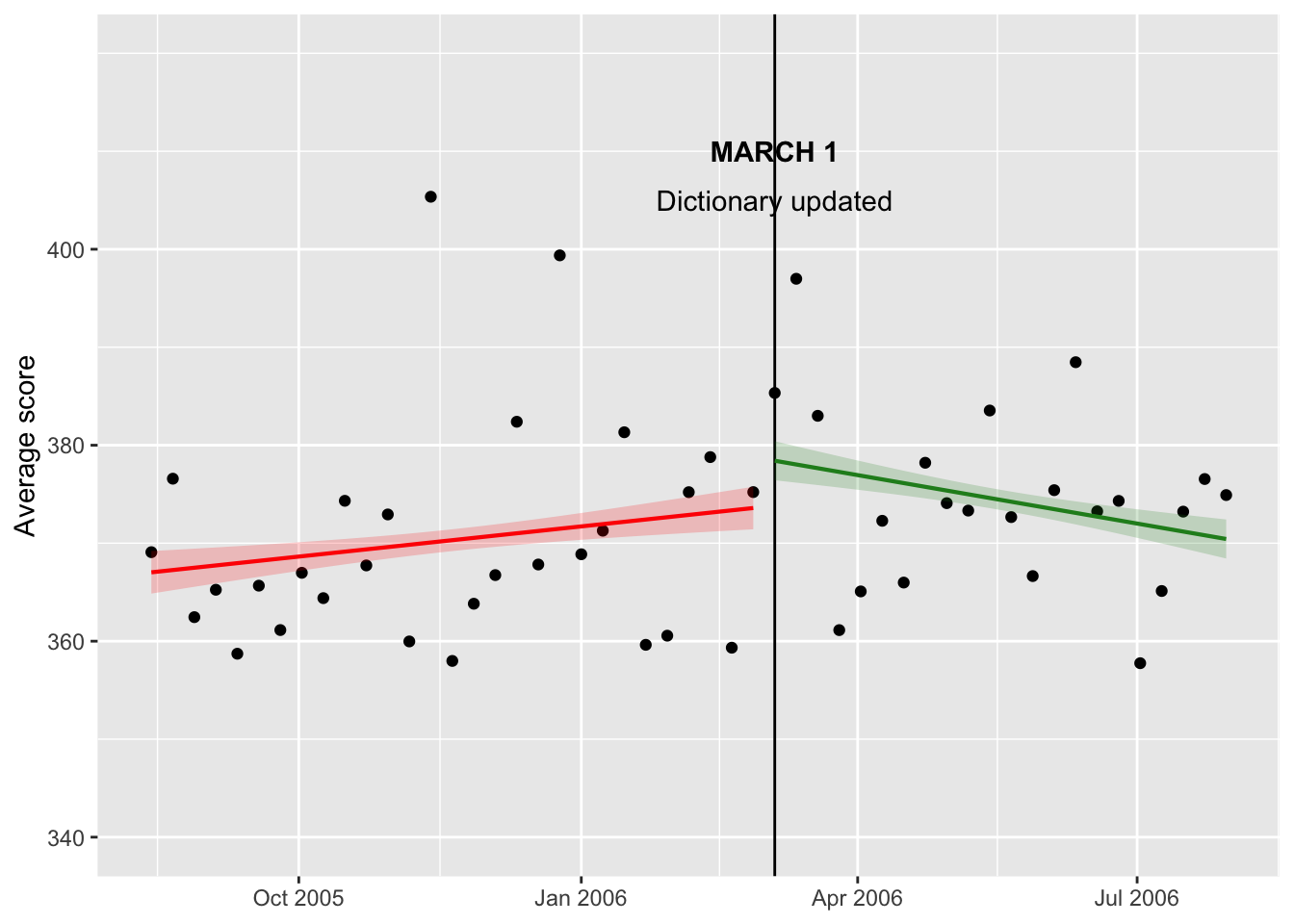
Alright, now we have some trendlines. I adjusted the level parameter by decreasing the confidence interval from 95% to 40% to achieve a similar look to the original figure. Now, I can try to adjust the color of the lines and points as well as add some more annotation.
Adjusting trendline color
weekdata %>% ggplot(aes(x = week, y = avg_score), ylim=c(340, 400)) + geom_point(fill="azure4", pch=21) +
theme(axis.title.x=element_blank()) + ylab("Average score") + scale_y_continuous(breaks = c(340, 360, 380, 400), limits = c(340, 420)) + geom_vline(aes(xintercept = as.numeric(week[30])))+
annotate(geom="text",x=as.Date("2006-03-05"),
y=410,label="MARCH 1",fontface="bold")+
annotate(geom="text",x=as.Date("2006-03-05"),
y=405,label="Dictionary updated")+
stat_smooth(method = "lm", formula = y ~ x, size = 0.75, se = TRUE, level = 0.40,
color = "darkorange", fill = "darkorange", alpha = 0.2,
data = weekdata[weekdata$week < as.Date("2006-03-05"),]) +
stat_smooth(method = "lm", formula = y ~ x, size = 0.75, se = TRUE, level = 0.40,
color = "darkorange", fill = "darkorange", alpha = 0.2,
data = weekdata[weekdata$week >= as.Date("2006-03-05"),])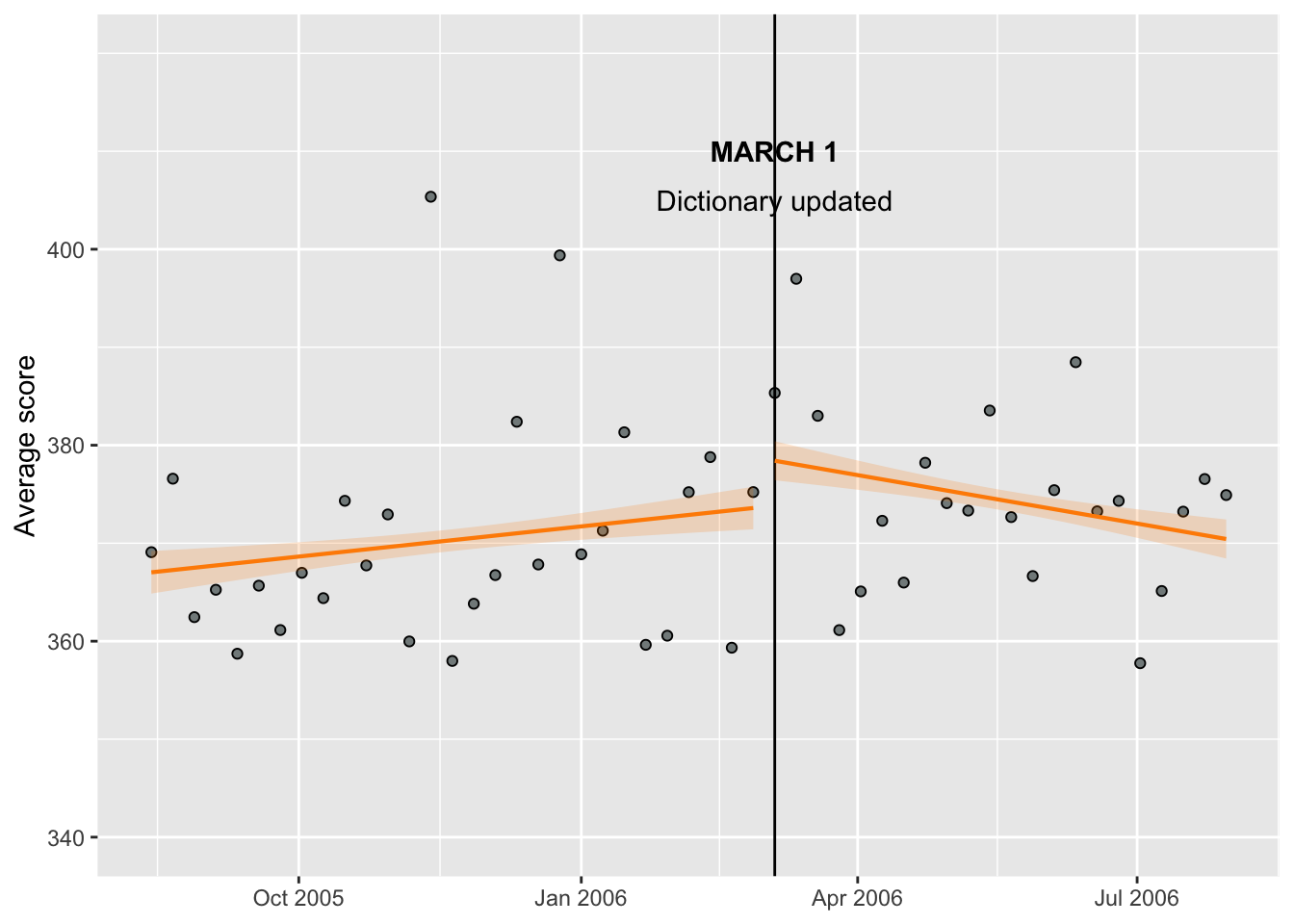
Ideally, I would like to decrease the font size for the annotation and make the March 5th line dotted. I also still need to add the text for before and after.
Final product
weekdata %>% ggplot(aes(x = week, y = avg_score), ylim=c(340, 400)) + geom_point(fill="azure4", pch=21) +
theme(axis.title.x=element_blank()) + ylab("Average score") + scale_y_continuous(breaks = c(340, 360, 380, 400), limits = c(340, 420)) + theme(axis.text = element_text(size=6), axis.title=element_text(size=6))+
geom_vline(aes(xintercept = as.numeric(week[30])))+
annotate(geom="text",x=as.Date("2006-03-05"),
y=410,label="MARCH 1",fontface="bold", size=2)+
annotate(geom="text",x=as.Date("2006-03-05"),
y=406,label="Dictionary", size=2)+
annotate(geom="text",x=as.Date("2006-03-05"),
y=402,label=" updated", size=2)+
stat_smooth(method = "lm", formula = y ~ x, size = 0.75, se = TRUE, level = 0.40,
color = "darkorange", fill = "darkorange", alpha = 0.2,
data = weekdata[weekdata$week < as.Date("2006-03-05"),]) +
stat_smooth(method = "lm", formula = y ~ x, size = 0.75, se = TRUE, level = 0.40,
color = "darkorange", fill = "darkorange", alpha = 0.2,
data = weekdata[weekdata$week >= as.Date("2006-03-05"),])+
annotate(geom="text", x=as.Date("2005-11-01"), y=380, label="Trend before", color="darkorange", size=2)+
annotate(geom="text", x=as.Date("2006-06-15"), y=380, label="Trend after", color="darkorange", size=2)+
annotate(geom="text", x=as.Date("2006-01-01"), y=350, label="Uncertainty", size=2, fontface='italic')+
geom_segment(aes(x=as.Date("2006-01-01"), y=351, xend = as.Date("2006-01-15"), yend = 370), size=0.25)+
theme(aspect.ratio = 1/1)+ #make figure square
ggtitle("Scrabble scores in the age of 'QI' and 'ZA'", "Weekly average scores before and after the addition of around \n11,000 words to the Scrabble dictionary") +
theme(plot.title = element_text(size=10, face="bold"))+
theme(plot.subtitle = element_text(size=9))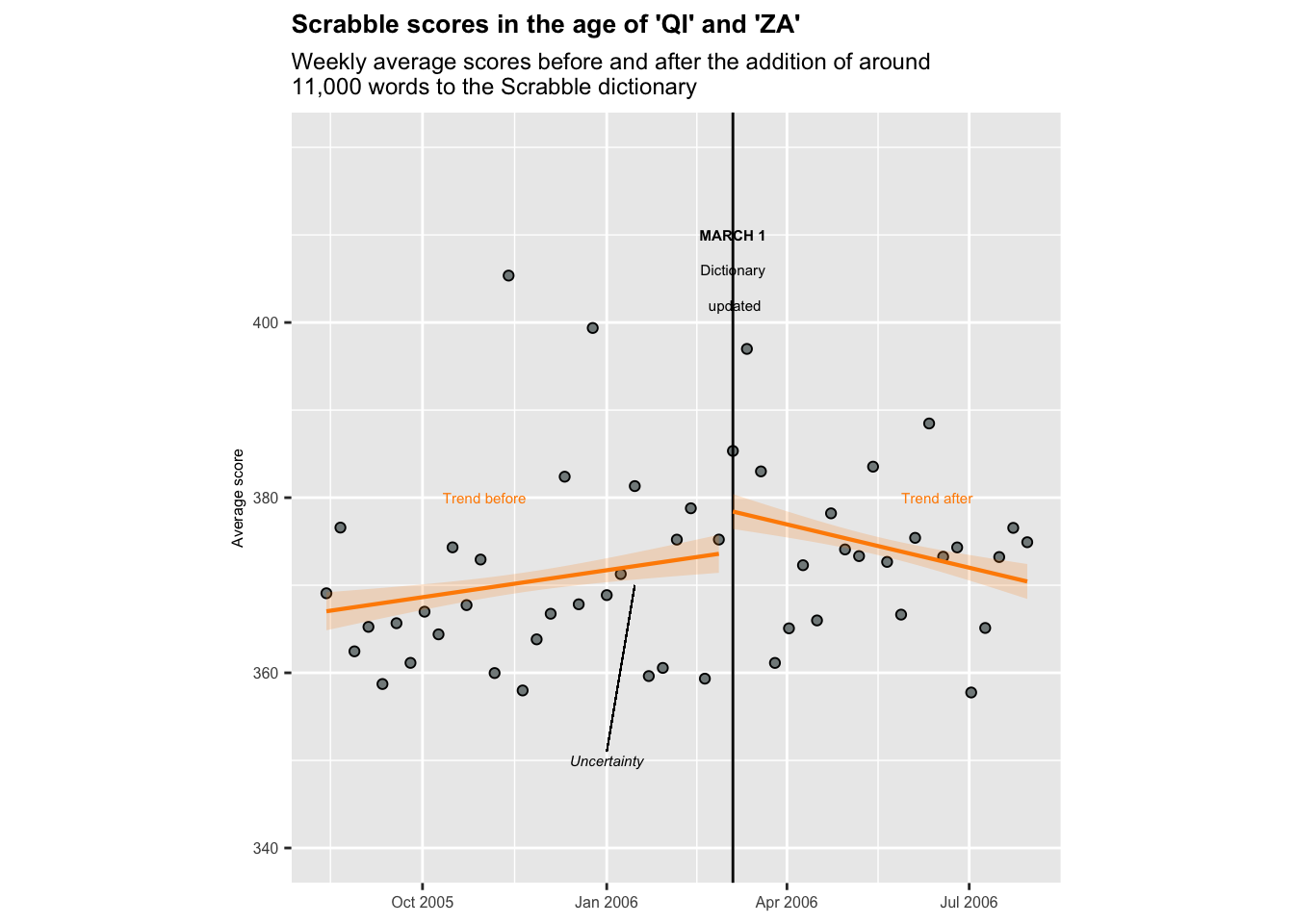
I noticed that the aspect ratio of my graph didn’t match the original, which was square, so I adjusted this in the previous code chunk. I couldn’t figure out how to make the March 1st line dotted, or how to clear a segment of it where the text is. However, I think the figure I have created looks decently similar to the original. I can tell that my data points are a little different than the original, which likely has to do with how the data was cleaned/wrangled. But, the same trends still stand - the change in Scrabble rules appears to have increased average scores among players.
Original